In this blog series, I will attempt to cover Azure Service Bus EventHub as a technology and how you can seamlessly integrate Event Hub with Microsoft Stream Analytics. We will then create an end to end Internet of Things (IoT) scenario leveraging these technologies.
EventHub Overview
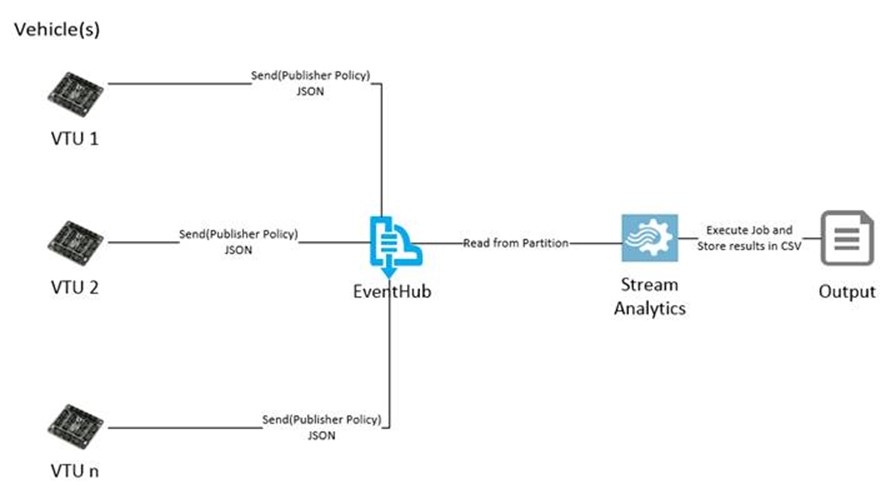
Event Hub is a hyper scale stream ingestion entity in Azure Service Bus. It allows for multiple client to publish events that can be persisted within event hub as streams of data, these event can then be used by consumer technologies like Microsoft Stream Analytics to transform it into useful information.
The service bus team has already done an excellent job in creating a comprehensive EventHub developer guide, so we will skip the introduction of EventHub but rather focus on the design patterns and implementation of EventHub with Stream Analytics.
If you are looking into a deeper feature overview of EventHub I would highly recommend you to go through the developer guide first.
I will be covering the following in this multi-part blog series:
- Design principles behind event hubs (this blog)
- Sending a consuming data using EventHub
- Using Microsoft Stream Analytics to make sense of data
Design principles behind EventHub
Cloud computing has changed the paradigm of building scalable applications. It has helped us to enable scenarios which were unrealistic in a privately owned data center.
The Internet of things is the next challenge for the cloud. Think of it this way, up till now cloud hosting providers were focused on scaling applications (of course there are many other benefits of cloud, but I focus on the “infinite” scale aspect for now). The uniqueness of scaling applications is that the demand of these applications on resources is intermittent. For example, a shopping portal can manage massive traffic by allocating more resources during peak hours and then minimizing during lean hours. This is the power and flexibility that the cloud presents us so we can operate in a cost effective way still maintaining customer expectations.
But, what is a lean scale scenario in case of Internet of things? Well, in most cases (especially Telemetry) there is none.
Think of a scenario – a vehicle designed to send telemetry data every 5 second will keep sending it unless it is interrupted because of a network or some other failure. This means that it does require a human to login into the Telematics Unit of the vehicle and the start the transfer of data, the vehicle may be transmitting all the time. It’s like a robot configured to send data without stop!
If you now extrapolate this scenario to a fleet of vehicles and now you have 1M devices sending continuous streams of data without interruption. So technically, the servers always need to respond to the requests to ensure adequate scale.
The above may not apply for all IoT scenarios, but this is a critical scenario for capturing telemetry data from the device. In most cases, the devices are flashed with firmware which has a connection module that reports consistent streams of data at frequent intervals.
So the question is, how do we effectively manage this humongous size?
You may say, add a pub sub messaging layer like a Topic or a Queue and that should take care of it, and it certainly will, however unless you have multiple Topics or Queue created, the pipeline will soon get saturated or require hyper scale at the consumer side to ensure you don’t reach the thresholds for these entities. This will also add more complexity on the development and cost of managing such systems.
Event hubs is targeted to solve such hyper scale IoT scenarios and is specifically targeted towards ingestion of data from several connected clients. Event hubs implements some interesting concepts to achieve this ridiculous scale, let’s look at some of these design principles:
-
Event Stream: From a design perspective event hub achieves high throughput by following a simple event stream log pattern. As events are sent, they are augmented to an event sink in an ordered fashion. Think of it as a giant funnel that allows authorized traffic to enter the system and keeps appending data fragments to a commit log. Events are segregated by partitions (more on partitions later) and may be accessed using time stamp or by an offset. Simplifying the architecture also applies some constraints, to enable high throughput event hub sheds some of the complex features available in other messaging system like sequencing, dead lettering, transactions etc. This, to me seems a reasonable trade off. Most IoT Telemetry scenarios that I have seen are more focused on achieving higher throughputs and some even do not care about loss of data. The main rational behind this is that the device is usually transmitting data at frequent intervals so if one packet is lost, the next update will provide the state of the device. (This of course does not apply for all telemetry scenarios.)
Note that although the messaging features in EventHub is simplified, it is still an enterprise grade messaging system and leverages the robust Service Bus and Azure infrastructure to meet the operational SLA’s.
-
Scale units: the concept of a scale unit is not new to Azure Service Bus, the existing service bus entities such as topics and queues also follow a scale unit design pattern. A scale unit in its simplified form is pre-allocation of resources to achieve deterministic scale targets. What this means is that the overall system is divided into groups of scale units where each scale units had some defined thresholds, these thresholds have been tested based on the resource allocation to the Scale Unit so it is somewhat guaranteed that the system will perform on optimum scale provided the ingress and egress targets stay within the scale unit thresholds. This is different from an auto scale approach where you keep adding resources dynamically as the load increases. While an auto scale approach works well for scenarios like web front ends or backend worker roles, dealing with a group of resources (such as database, backend nodes etc. together) can make auto scaling complicated. Furthermore, a scale unit provide a degree of isolation thus improving security, if a malicious user is able to hack into the system one the specific scale unit is impacted. Another benefit of scale units is parallel deployment and testability of components, you may upgrade one scale unit in a smaller region with a beta release while the critical geographies continue using the stable version. Event hubs enable the scale unit pattern by Throughput units, a single throughput unit provides:
- Ingress: Up to 1MB per second or 1000 events per second.
- Egress: Up to 2MB per second.
Throughput units are billed at an hourly interval, in the current release you can purchase up to 20 throughput units for a service bus namespace.
- Ingress: Up to 1MB per second or 1000 events per second.
-
Partitioned Consumers: Partitions allow for efficient organization of data within EventHub and basically are used to build a log of ordered event streams within EventHub. This of partitions in EventHub as data shards. Partitions play a pivotal role in the classification of data within event hub and also determine how load within event hub will be distributed. Load distribution of a partition however does not correlate to the throughput of EventHub, partitions are more focused in allowing consumers to retrieve data streams more efficiently, and throughput units should be used for improving throughput of the system. An EventHub can have multiple data-isolated partitions, the GA release supports up to 32 partitions but this can be increased by opening a support ticket with Microsoft Azure team.
EventHub employ a Partitioned Consumer pattern where consumers receive messages on a partition rather than on the entire message stream. This is different from to a service bus Queue or Topic which leverages a Competing consumer pattern allowing multiple clients to read from a single message stream. The benefit of a Partitioned Consumer is that since there is data isolation amongst partitions you can now direct consumers to specific partitions (data shard) reducing the overall load on the messaging layer. Also this approach can allow for segregating Consumers by functionality (using Consumer Groups) and even scale out based on partition load.
-
Granular identity Management: EventHub leverage the SAS (Shared Access Token) model already available in Azure Service Bus to provide a much granular control on publishers and consumers. This is very relevant to an IoT scenario where you would want each sending device to have its own unique identity, EventHub achieves this through Publisher policies for Client sending event streams.
Now that we have an understanding of the EventHub design principles, let’s start working on building our scenario. In the next section, we create a .NET based publisher and consumer for event hub to send and receive data.