My dear buddy Matt Long did a great experiment of building a full fledged hot air balloon driven gadget to capture Telemetry data and issue Command to space!
Check out the details of the Pegasus mission here:
human.machine.internet
My dear buddy Matt Long did a great experiment of building a full fledged hot air balloon driven gadget to capture Telemetry data and issue Command to space!
Check out the details of the Pegasus mission here:
In this blog series, I will attempt to cover Azure Service Bus EventHub as a technology and how you can seamlessly integrate Event Hub with Microsoft Stream Analytics. We will then create an end to end Internet of Things (IoT) scenario leveraging these technologies.
EventHub Overview
Event Hub is a hyper scale stream ingestion entity in Azure Service Bus. It allows for multiple client to publish events that can be persisted within event hub as streams of data, these event can then be used by consumer technologies like Microsoft Stream Analytics to transform it into useful information.
The service bus team has already done an excellent job in creating a comprehensive EventHub developer guide, so we will skip the introduction of EventHub but rather focus on the design patterns and implementation of EventHub with Stream Analytics.
If you are looking into a deeper feature overview of EventHub I would highly recommend you to go through the developer guide first.
I will be covering the following in this multi-part blog series:
Design principles behind EventHub
Cloud computing has changed the paradigm of building scalable applications. It has helped us to enable scenarios which were unrealistic in a privately owned data center.
The Internet of things is the next challenge for the cloud. Think of it this way, up till now cloud hosting providers were focused on scaling applications (of course there are many other benefits of cloud, but I focus on the “infinite” scale aspect for now). The uniqueness of scaling applications is that the demand of these applications on resources is intermittent. For example, a shopping portal can manage massive traffic by allocating more resources during peak hours and then minimizing during lean hours. This is the power and flexibility that the cloud presents us so we can operate in a cost effective way still maintaining customer expectations.
But, what is a lean scale scenario in case of Internet of things? Well, in most cases (especially Telemetry) there is none.
Think of a scenario – a vehicle designed to send telemetry data every 5 second will keep sending it unless it is interrupted because of a network or some other failure. This means that it does require a human to login into the Telematics Unit of the vehicle and the start the transfer of data, the vehicle may be transmitting all the time. It’s like a robot configured to send data without stop!
If you now extrapolate this scenario to a fleet of vehicles and now you have 1M devices sending continuous streams of data without interruption. So technically, the servers always need to respond to the requests to ensure adequate scale.
The above may not apply for all IoT scenarios, but this is a critical scenario for capturing telemetry data from the device. In most cases, the devices are flashed with firmware which has a connection module that reports consistent streams of data at frequent intervals.
So the question is, how do we effectively manage this humongous size?
You may say, add a pub sub messaging layer like a Topic or a Queue and that should take care of it, and it certainly will, however unless you have multiple Topics or Queue created, the pipeline will soon get saturated or require hyper scale at the consumer side to ensure you don’t reach the thresholds for these entities. This will also add more complexity on the development and cost of managing such systems.
Event hubs is targeted to solve such hyper scale IoT scenarios and is specifically targeted towards ingestion of data from several connected clients. Event hubs implements some interesting concepts to achieve this ridiculous scale, let’s look at some of these design principles:
Note that although the messaging features in EventHub is simplified, it is still an enterprise grade messaging system and leverages the robust Service Bus and Azure infrastructure to meet the operational SLA’s.
Throughput units are billed at an hourly interval, in the current release you can purchase up to 20 throughput units for a service bus namespace.
EventHub employ a Partitioned Consumer pattern where consumers receive messages on a partition rather than on the entire message stream. This is different from to a service bus Queue or Topic which leverages a Competing consumer pattern allowing multiple clients to read from a single message stream. The benefit of a Partitioned Consumer is that since there is data isolation amongst partitions you can now direct consumers to specific partitions (data shard) reducing the overall load on the messaging layer. Also this approach can allow for segregating Consumers by functionality (using Consumer Groups) and even scale out based on partition load.
Now that we have an understanding of the EventHub design principles, let’s start working on building our scenario. In the next section, we create a .NET based publisher and consumer for event hub to send and receive data.
In Part 2 of this blog series, we created an EventHub and a publisher to send Vehicle Stream data. We also created a consumer for testing our published messages. In this final post, we will look at Microsoft Stream Analytics and how it provide Out Of Box capabilities of processing EventHub data streams in real time.
Introducing Stream Analytics
Stream Analytics is Microsoft answer to real time event processing. It can be employed to enable Complex Event processing (CEP) scenarios (in combination with EventHubs) allowing multiple inputs to be processed in real time to generate meaningful analytics. Technologies like Esper and Apache Storm provide similar capabilities but with Stream Analytics you get an out of box integration with EventHub, SQL Databases, Storage, which make it very compelling for development in Microsoft Azure.
Moreover, it exposes a query processing language which is very similar to SQL 92 syntax, so the learning curve is minimal. In fact, once you have a job created, you can simply use the Azure Management portal to develop queries and run jobs eliminating the need to coding for most use cases. For more information on Stream Analytics refer here.
Let’s leverage Stream Analytics for the Event Hub scenario we development in the previous blog:
Creating a Stream Analytics job
Stream Analytics is still in Preview so the first task is to enable it as a feature for your Azure Subscription.
For limitations of the preview release in creating job refer here.
To do this, login to your Azure subscription account administration. Select your subscription, then choose preview features, scroll down and Click “try it now” against the Stream Analytics option.
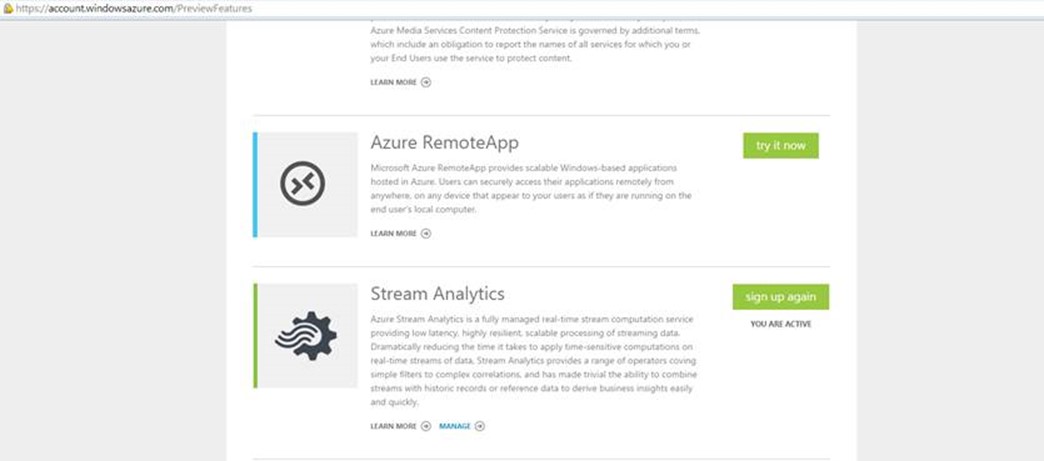
Once activated you should see a Stream Analytics extension in your management portal:

You can now start creating Stream Analytics jobs. A job in stream analytics allows you to define the inputs, query logic and outputs for a scenario.

Defining Inputs
The next step is define Inputs for our job, Click on the job we just created and select Input -> Add an Input
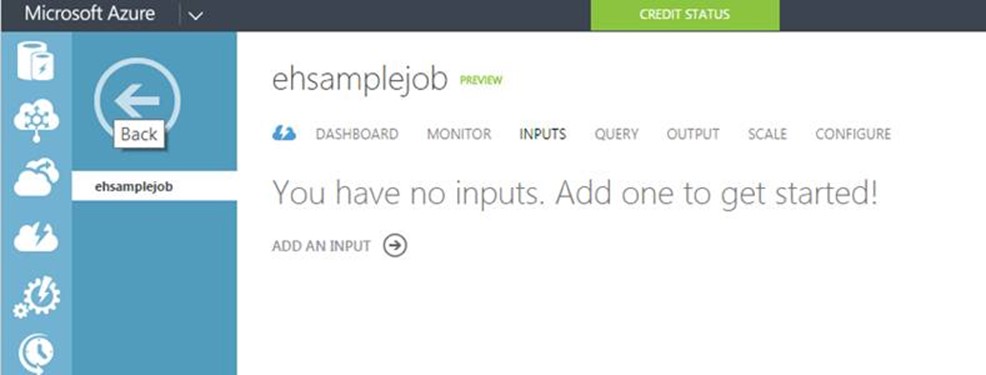
There are currently two types of Input that can be added:
When building a query both inputs appear as dataset that you can include in your query.
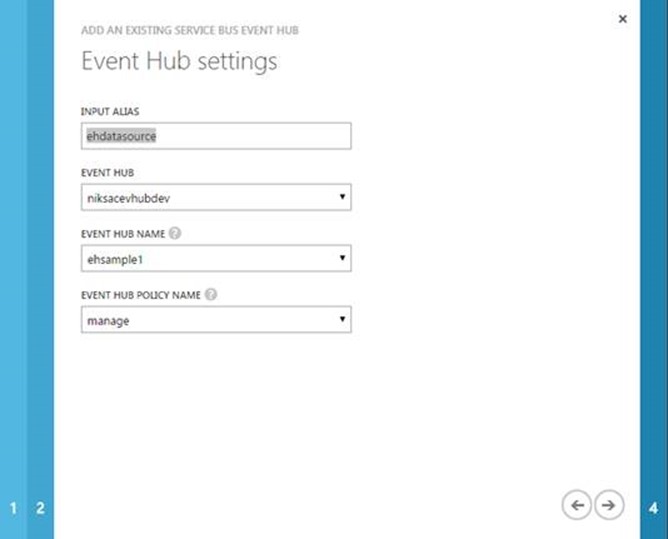
For our scenario, we will use EventHub as the data stream:



Defining Output
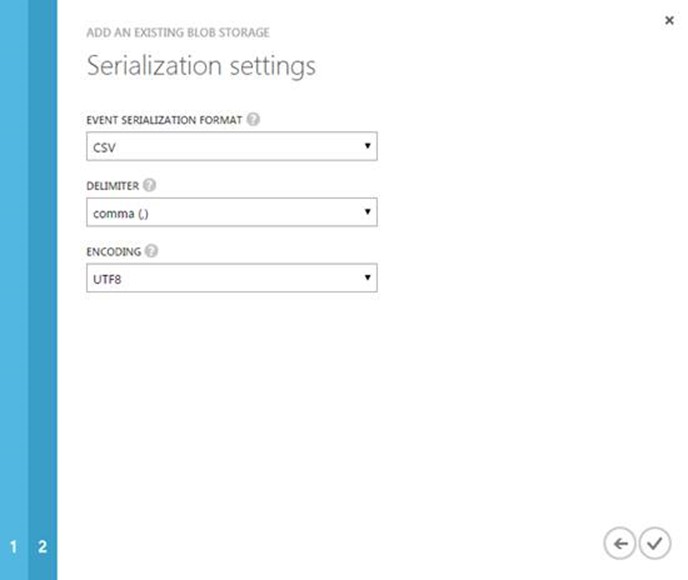
Before we define a query, we will provide an output for our results

Defining the Query
Now we come to the interesting part of Stream Analytics, as mentioned before Stream Analytics allows users to create SQL-like syntax for processing of ingestion data streams. The query language that enables this feature is the Stream Analytics Query language. Most of the syntax and constructs of SQL 92 are supported however there are some very interesting additions:
Windowing
As the name suggests, Windowing allows for processing data stream within a window of interval. It is mainly handling events that occurred on a slice of the timeline. Stream Analytics does the aggregation over the duration of the window specified. Windowing is always used in the GROUP BY clause.
There are three variations of Windowing that is supported:
For our scenario, we will create a query that will process based on the following business logic:
For the last five minutes, output the count all vehicles where average odometer reading is > 10000.
This can be used by dealers to determine which vehicles are due lease renewals.
Don’t worry if this condition sounds unrealistic, the idea here is to show the simplicity of query development in Stream Analytics, you can create more powerful use cases using the query language:
To define the query, we simply access the Query tab in the Management Portal to enter a query. The Query window itself is very similar to an SQL query window and provides basic syntax validation. It does not have features like running query for results at least today, you will have to execute the job to view the results.

Running our Job and results
Let’s recap what we have done until now, we created a new Stream Analytics Job and defined the Input, Output and Query to be processed. The next step is to run the job. This can simply be done by pressing Start on the Dashboard tab. This will verify the Input and Output connection and then also validate the Query before execution.

Once all validation are successfully completed, Stream Analytics will provide a status on the job. Your job is now reading incoming streams from the EventHub. Think of this as a consumer to your EventHub which will process all incoming data streams.

Now that we have a job running, the final step is to push some event data into the event hub to validate our results. I will use the Publisher that we created in Part 2 of this blog to publish messages on the EventHub. The publisher is a simulator which send event streams for different devices and also repeats status from already sent device to create a mix of incoming data streams.

If you now go and look at the Storage account and the Blob container we mentioned when configuring the Stream Analytics Output, you should see a CSV created. Opening the CSV provides us with the expected results.

Great, we now have real-time results getting processed from our device Telmetry!
If you want to monitor the requests being processed by the Stream Analytics job, you can view the Dashboard in Management Portal and you should see Input and Output events getting processed.

EventHub and Stream Analytics are really powerful techniques that can be used to create end-end IoT solutions. With the support of protocols like AMQP, Https you can cater a lot of new generation powered devices and use these technologies in conjunction to ingest telemetry data from a variety of clients. In case, your devices work on other custom protocol or protocol like MQTT you may still be able to create a front end (protocol head) that accepts request and then transforms the packet in AMQP. From that point onwards you can continue to use EventHub for ingestion and Stream analytics for real-time processing.
In Part 1 of this multi-part series blog, we talked about EventHubs and the design patterns that enable it to perform at high throughputs. In this blog post we will create use EventHub for collecting data from a publisher, we will also create a Consumer that can receive the published events.
Problem Scenario
Our problem situation is a fictitious automotive company Contoso Motor Works (CMW). CMW has built their next generation Telemetry system to collect frequent data streams from the vehicles. The data will be used for performing preventive maintenance and near real time analytics for example to provide notifications to the driver in case the engine oil goes below the level. Contoso has chosen EventHub and Stream Analytics to achieve the anticipated scale for their North America vehicle rollout.
The high-level design looks something like this:
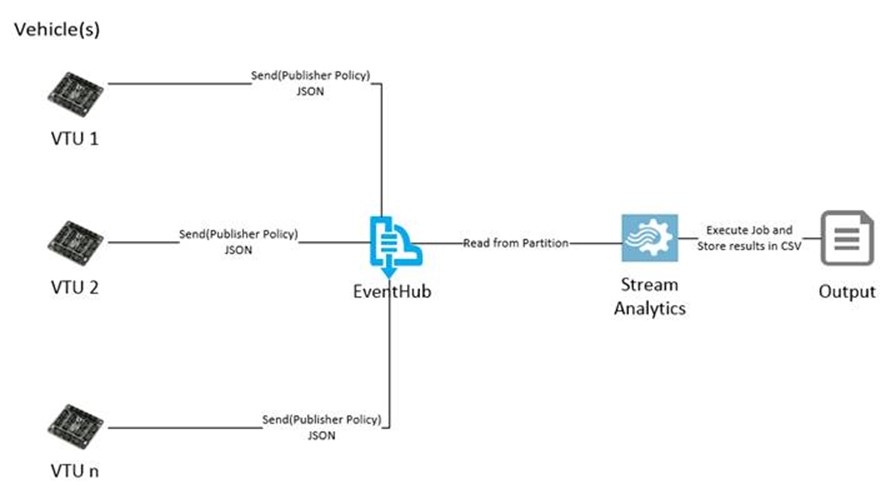
Note that since this is a simplified scenario we only output the results in a CSV. In a real world scenario, you can do more powerful stuff such push the results into another EventHub and have a Consumer that sends push notifications using Notification Hubs, etc. I will cover some of those in the next section of this series.
Creating our Data Model
We need to represent Telemetry data from the Vehicle that will be sent as the Event datastream, the following represents a simplistic model for our fictitious scenario:
public class VehicleStream : Entity |
{
public int TirePressure { get; set; } // Ignore using psi, using a standard int
public int FuelGaugeLevel { get; set; }
public int EngineOilLevel { get; set; }
public int OdoMeterReading { get; set; }
public bool VTUStatus { get; set; }
}
Continue reading “Building an IoT solution with Azure Event Hubs and Stream Analytics – Part 2”
Gartner Identifies Four Fundamental Usage Models to Unlock Value from the Internet of Things: http://www.gartner.com/newsroom/id/2699017
Manage — Looking at the Status of the Asset to Improve Utilization
This model is essentially involved in the optimization of asset utilization within an environment. As various assets (which could be a device or piece of equipment, or a location, such as a meeting room or a parking space) are connected and are able to provide up-to-date status information, then utilization can be optimized through appropriate systems to match assets with needs. The assets may be simple and report very limited data (occupied or vacant, for example), or they could be very complex (such as a jet engine) and involve multiple sensors reporting real-time streams of data, which may amount to terabytes per hour — but this does not detract from the essential value model.
Monetize — Charging for Usage of the Asset on an Incremental Basis
This is a specific business model that is about the monetization of a physical asset by accurately measuring usage. It enables a (potentially very expensive) capital asset to be used as the basis for a usage-based service. This brings business opportunities to replace capital expenditure with operating expenditure, more-accurate plotting of product life cycle and more-effective preventive maintenance. An example is monitoring engine hours, actual load, fuel usage and so on of a piece of equipment to bill usage against actual wear and tear. By combining this information with location, speed and time information, the enterprise can accurately assess additional charges to reflect the risk. This could apply to a “pay as you drive” vehicle insurance service, a clear example of the application of this use case to physical objects not actually owned by the enterprise itself.
Operate — Using the Asset to Control Its Surroundings
This model builds on the well-established realm of “operational technology,” which is technology used to manage the equipment and processes inside manufacturing plants. Operational technology is increasingly moving away from the proprietary and isolated architectures of the past to exploit more mainstream technology, software and architectures and, in doing so, coming in some cases under the CIO’s and the IT department’s purview. Simple examples to control a valve, but in a more complex example, the data from thousands of sensors might combine weather and atmospheric conditions with water flow, pressure and depth information to manage entire water supply or irrigation systems. It will reduce the need to physically visit the remote device, and avoid hazardous environmental conditions around the device.
Extend — Providing Additional Digital Information or Services Through an Asset
A physical supply chain ends when a product or asset is shipped. However, when that asset is connected, a digital supply chain continues to exist in which digital services and products can be delivered to that asset. In effect, the physical asset is extended with digital services. Simple examples might be automatic (perhaps subscription-based) downloads of firmware to a device to provide new capabilities or rectify newly identified faults. Owners of a connected automobile may download the ability to upgrade or extend the driving mode of the car. More-complex examples might be the provision of advisory information (such as imminent part failure, and excessive wear or overheating of a device) to avoid the costs of failure through preventive action. Media content is a digital product that could be sent to any connected asset, such as streaming movies to a train seat.
“Although much of the spotlight today is on the Internet of Things, the true power and benefit of the Internet comes from combining things with people, places and information systems,” said Hung LeHong, vice president and Gartner Fellow. “This expanded and comprehensive view of the internet is what Gartner calls the Internet of Everything.”
What’s new about this, so you would ask?
Internet of Things aka IoT is already making a big impact in our day-to-day lives, the fact that the IoT industry became a $1.24 trillion (Source: Markets and Markets) business in 2013 proved that IoT is big and here to stay. However the reason I say this is not because how many under 25 billionaires it will create but how it is going to change our lives forever.
This realization came to me just recently …
the other day my wife was making tea and she realized we were out of sugar (yeah I forgot it during the last visit to the grocers, how that ended for me is another story) and said “I wish someone can fill this up magically every time!” … Now if this was some years back I would be thinking of Aladdin and his Genie but with the advent of IoT I started thinking this might just be possible …
Consider a “Smart Jar” that has sensors which track its quantity, the consumer can set a configuration of sending alerts whenever the quantity reaches below a minimum limit, the device can then send notifications to the user or add the item to their favorite grocery list app. Taking this a step further the “Smart Jar” can connect to an external provider like Amazon or Target which the user has a subscription for (in USA) and then automatically schedule the item for next delivery. Also for people like me who constantly forget the location of items in the kitchen a mobile app lets you find the appropriate jar based on its co-ordinates. From a producer perspective the jar may send telemetry on usage pattern for families which can show demographics on how products are used.
While the above example may seem a little overreached (btw some start u p might just be working on a solution for this right now!) the point I was trying to make with the example above is that many such tasks that touch our daily lives will be simplified and automated with the use of connected devices. This, by itself will be a revolution not just in our homes but for corporate as well. It will change how we eat, drink, shop … live and that is why I say it is the next big bang!
p might just be working on a solution for this right now!) the point I was trying to make with the example above is that many such tasks that touch our daily lives will be simplified and automated with the use of connected devices. This, by itself will be a revolution not just in our homes but for corporate as well. It will change how we eat, drink, shop … live and that is why I say it is the next big bang!
Now the next question that comes to mind is … are we ready for it?
Many governments and companies are investing generously in the research and development for IoT solutions (Industry 4.0). This is great for the IoT industry, however any industry needs consistent sales to sustain and prosper. We have seen successes in certain domains such as connected homes and thermostats (Nest) , automobile (BMW), wearable etc but there is still so much untapped potential that this just seems like the tip of the iceberg.
One of the big challenges for any industry is adoption; since the events we are talking here are life changing there are certain principles that should be followed when building devices targeted for IoT to enable mass adoption:
Intuitive: When the iPad was launched several years back it lacked a lot of features but one thing that was prominent in the device was that it looked “sexy” and simplified a lot of tasks that were cumbersome on a laptop or a desktop (aka the dinosaurs that existed some years back) and that was one of the main reasons of its success. History was repeated when Nest launched its smart thermostat which though may not be completely accurate from a temperature or humidity perspective provides great intuitive features that has compelled major manufacturers in this field to release similar variants. So any device that will be launched under the IoT umbrella needs to be intuitive and simplified rather than sophisticated. Some key features that any device may exhibit:
Privacy and Security: Security is an obvious concern and has been highlighted in many articles. With multiple devices running all the time and sending telemetry data back to manufactures they can literally predict what you are doing right now in your house. This is an invasion in privacy which both consumers and corporate will oppose to. Simply put, convenience at the stake of privacy will not sell!! We are still in an immature stage in this space but work is being done to define policies around data privacy and end-user security. This is an area I would be watching before placing my bets on IoT.

Cost: A device by itself does not achieve an IoT scenario, it needs to be backed with the power of cloud and data analytic so when evaluating the cost of a device multiple auxiliary items need to be accounted for such as:
These are just high level items, there are multiple hidden costs apart from these that need to be constituted in the selling price of the device. Now all these details make a compelling reasoning for the costs to be higher than a normal device, however the consumer does not care about what goes in the device or that a sophisticated cloud platform is backing the solution (at least not from a cost perspective), a light bulb is a light bulb and if a consumer gets it for 10x of the average price only a small community would be interested in it most likely for experimental purposes. It is thus essential to keep the costs to the minimum.
An effective way can be to keep the device price low and provide subscription based solution for enabling more features on the device. Also as the hardware manufacturing costs keep coming down we will see many of these devices become reachable to the masses.
Interoperability: This is always a hot and controversial topic for me, Hot because just thinking of interoperability as part of IoT standards opens up a plethora of opportunities and can introduce huge gains to consumers. Controversial because a lot of companies today bet their business on their platform, example Windows for Microsoft and iOS for Apple, so from a business perspective if you have a closed platform people will get tied to it and most likely will stick to it for years to come. Besides once you get people on your platform it is easy to sell them supplement services that are optimized for that platform, for example YouTube experience on an Android device is far better as compared to YouTube on a Windows phone.
Now platform dominance was OK for the PC, tablet and phone market primarily because of their controlled production and legacy proficiency but the IoT introduces a whole new generation of devices and it seems almost impossible that companies can become successful without providing an open and inter-operable interface.
Think of an example, your microwave needs to get input from your refrigerator so it knows at what temperature it should warm the food at and for how much time (example shamelessly stolen from the ebook published by CoAP sharp team). Now the microwave is from Samsung but the refrigerator is from LG, the only way they can talk to each other is through a common platform. Now apply this to the hundreds of devices that you will have in your house, automobile, and offices in the coming years that are developed in different countries and by different manufacturers, unless they all have some common form of Interfaces to communicate the IoT vision and goals will not be achieved. Agreed that there will be companies that will create some middle ware such as Belkin Wemo Smart Switch but I would consider these as alternatives to legacy devices, anything new should be inter-operable by design.(period)
I will talk more about work being done in this space in a future post.
Infrastructure: Cloud Computing has been a game changer in how business’s work, it enables organizations to have the impression of unlimited resources for any of their computing needs and that too at a cheaper cost. Well unlimited is a stretch right now since most cloud providers have some restrictions and bars defined on your usage but these limits are still too high for most of business’s. Moreover if required organizations can put in a bag of money to have their own silo data centers in order to achieve their scalability targets, this is still cheaper than hosting and maintaining everything in their in-house data centers.
This all works very well for almost 99% of the Web and Mobile scenarios today however the IoT space is different from how Web and Mobile applications operate:
Most Web and Mobile solutions require human intervention so the spike or bursts in the server load is intermittent or during standard schedules such as peak hours, in case of devices however this load is constant, for example, if a thermostat is configured to send telemetry data back to the server every 30 seconds that is a constant activity that the device will continue to perform unless it breaks due to some failure, it does not stop for lunches or take bio breaks it just keeps transmitting data every 30 seconds. Now consider 10 Million of these thermostats deployed across continents and each thermostat transmits around 10 KB of data (including headers and payload) . We are talking about 100000000 KB (95.4 GB) of data being sent for processing and storage at a constant rate of 30 seconds. This is huge and while the cloud might still be able to accommodate such loads through Big data and Auto Scaling the small and medium business’s would have challenges managing the costs of running such solutions. Note that I have described a simple ingestion scenario above, add the data coming from mobile application commands, device inquiry etc. and this number just keeps growing.
There is no silver bullet to the explosion of data and how back ends will manage it while still keeping the costs low, as we mature more in the Cloud space we should see price drops in Cloud computing and storage solutions which should bring the overall costs down, also optimization on the device payload and messaging can ensure minimal data being sent over the wire (Protocols like MQTT and CoAP are being designed for such type of solutions)
So where do we go from here?
IoT is one the best things that has happened in the our space, it has blurred the lines between the hardware and software industry, enabled scenarios that we could only see in movies or dream about however there is a need for standardization of how companies design and implement solutions, instead of working in silos we need to work towards a consistent and effective reference solution that may apply to most if not all scenarios. Of course there will be tweaks and turns for each sub domain but if the basic principles and not violated with we are looking towards a new world that will change how we work today … this will truly be a big bang!
